Thread and Task Architecture Guide
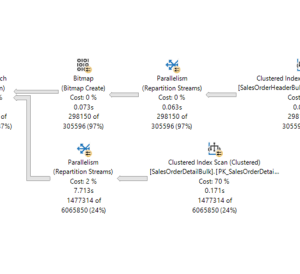
Operating system task scheduling Threads are the smallest units of processing that can be executed by an operating system, and allow the application logic to be separated into several concurrent execution paths. Threads are useful when complex applications have many tasks that can be performed at the same time. When an operating system executes an instance of an application, it creates a unit called a process to manage the instance. The process has a thread of execution. This is the series of programming instructions performed by the application code. For example, if a simple application has a single set of instructions that can be performed serially, that set of instructions is handled as a single task, and there is just one execution path (or thread) through the application. More complex applications may have several tasks that can be performed concurrently instead of serially. An application can do this by starting separate processes for each